今天的教學內容要教各位如何將訓練好的模型儲存,並提供下一次載入模型和預測。在本系列的教學中介紹了許多 Sklearn 的模型演算法。當模型訓練好了,可以將訓練結果儲存起來,並建立一個 API 接口提供模型預測。
常見的儲存模型的套件有 pickle 與 joblib。其中在 [Day 20] 機器學習金手指 - Auto-sklearn 最後有使用 joblib 來儲存模型,操作方法也非常簡單。然而在今天的教學中則使用另一種方法 pickle 來儲存模型。由於 pickle 儲存模型後容量可能會有好幾百 MB 因此建議可以透過 gzip 來壓縮模型並儲存。另外在 Python 官方文件中有警告絕對不要利用 pickle 來 unpickle 來路不明的檔案。因為透過 pickle 打包模型會有安全性疑慮,包括 arbitrary code execution 的問題,詳細內容可以參考這篇文章。如果要追求執行速度與安全性,建議可以採用 JSON 格式來存取模型的參數與設定。
後記:這幾年ONNX模型通用格式也非常流行,除了神經網路之外也支援sklearn的模型儲存。大家不妨也可以試試看!
今日的範例還是拿鳶尾花朵資料集進行示範。首先我們先載入資料集並進行資料的切割。
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.datasets import load_iris
iris = load_iris()
df_data = pd.DataFrame(data= np.c_[iris['data'], iris['target']],
columns= ['SepalLengthCm','SepalWidthCm','PetalLengthCm','PetalWidthCm','Species'])
df_data
from sklearn.model_selection import train_test_split
X = df_data.drop(labels=['Species'],axis=1).values # 移除Species並取得剩下欄位資料
y = df_data['Species'].values
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42, stratify=y)
print('train shape:', X_train.shape)
print('test shape:', X_test.shape)
XGBoost 模型是目前最熱門的演算法模型之一,詳細的內容可以參考 [Day 15] 機器學習常勝軍 - XGBoost。裡面會有介紹詳細的模型說明與手把手實作。當然大家也可以試著用其他 Sklearn 的模型訓練看看,一樣可以透過 pickle 來儲存訓練好的模型。
from xgboost import XGBClassifier
# 建立 XGBClassifier 模型
xgboostModel = XGBClassifier(n_estimators=100, learning_rate= 0.3)
# 使用訓練資料訓練模型
xgboostModel.fit(X_train, y_train)
# 使用訓練資料預測分類
predicted = xgboostModel.predict(X_train)
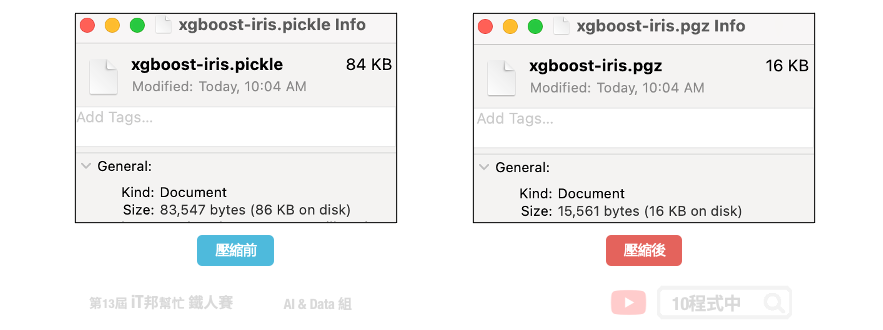
大家可以觀察 .pickle 與 .gzip 兩種不同副檔名儲存結果檔案大小有何差別?
import pickle
with open('./model/xgboost-iris.pickle', 'wb') as f:
pickle.dump(xgboostModel, f)
import pickle
import gzip
with gzip.GzipFile('./model/xgboost-iris.pgz', 'w') as f:
pickle.dump(xgboostModel, f)
試著載入兩種不同格式的模型,並預測一筆資料。注意模型預測輸入必須為 numpy 型態,且須為二維陣列格式。
import pickle
import gzip
#讀取Model
with gzip.open('./model/xgboost-iris.pgz', 'r') as f:
xgboostModel = pickle.load(f)
pred=xgboostModel.predict(np.array([[5.5, 2.4, 3.7, 1. ]]))
print(pred)
#讀取Model
with open('./model/xgboost-iris.pickle', 'rb') as f:
xgboostModel = pickle.load(f)
pred=xgboostModel.predict(np.array([[5.5, 2.4, 3.7, 1. ]]))
print(pred)
雙十1010連假愉快
文章同時發表於: https://andy6804tw.github.io/crazyai-ml/28.儲存訓練好的模型
如果你對機器學習和人工智慧(AI)技術感興趣,歡迎參考我的線上免費電子書《經典機器學習》。這本書涵蓋了許多實用的機器學習方法和技術,適合任何對這個領域有興趣的讀者。點擊下方連結即可獲取最新內容,讓我們一起深入了解AI的世界!
👉 全民瘋AI系列 [經典機器學習] 線上免費電子書
👉 其它全民瘋AI系列 這是一個入口,匯集了許多不同主題的AI免費電子書
10程式中 你好, 看了您一系列的文章下來到這個階段, 有個想請教, 如果訓練跟測試模型時都是使用這個function去執行(這datafram有多個season),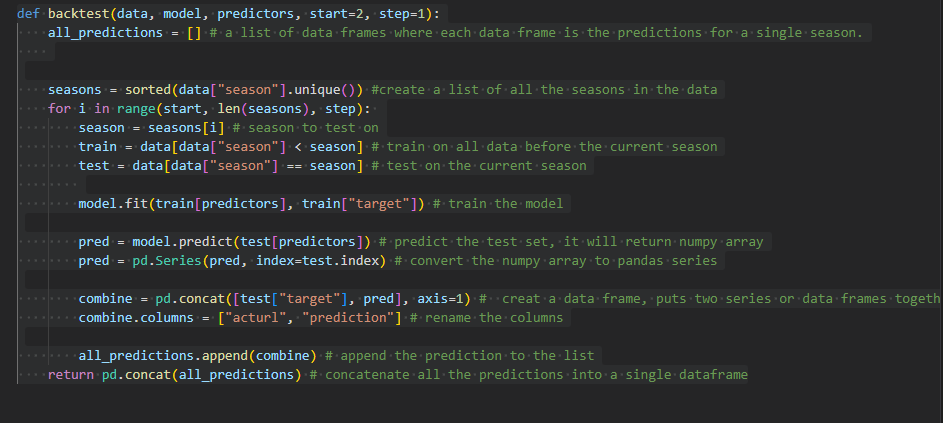
那將訓練好的模型存下來以後要使用, 但是輸入要測試的datafram的column數 必須要相同於train時用的feature 數量, 若手邊有的測試數據 沒辦法吻合 測試時用的features, 請問是該更改測試數據 還是訓練數據?
非常感激您有空可以幫我解答, 謝謝
Hi Rick


 iThome鐵人賽
iThome鐵人賽